前言 本篇文章是笔者在自学Python爬虫相关技术时作的笔记。多线程/进程异步编程的目的在于通过提升CPU的工作效率来提高代码的运行速度。在实际操作时就会发现,Python相关的库和操作系统帮助我们完成了大量的操作,我们只需要指定相关的任务,具体的任务调度不需要开发者关心。这也是使用Python进行异步编程的优势所在。
声明:本文章仅探讨技术,分享相关经验。请勿使用相关技术进行任何违法行为,否则将承担法律责任。
- Python版本:3.12(基于anaconda)
- Pycharm版本:2024.1
1 线程和进程
线程可以理解为一个程序中不同的道路,这些不同的道路存在于它所属于的进程中。进程是一个资源消耗单位,对于一个程序来说,在开始运行时它就一定会占用系统中一定的内存,此时它就被赋予一个新名称:进程。一个进程包括加载到内存中的可执行代码,CPU状态,分配给进程的内存区域,打开的文件列表,IO设备。
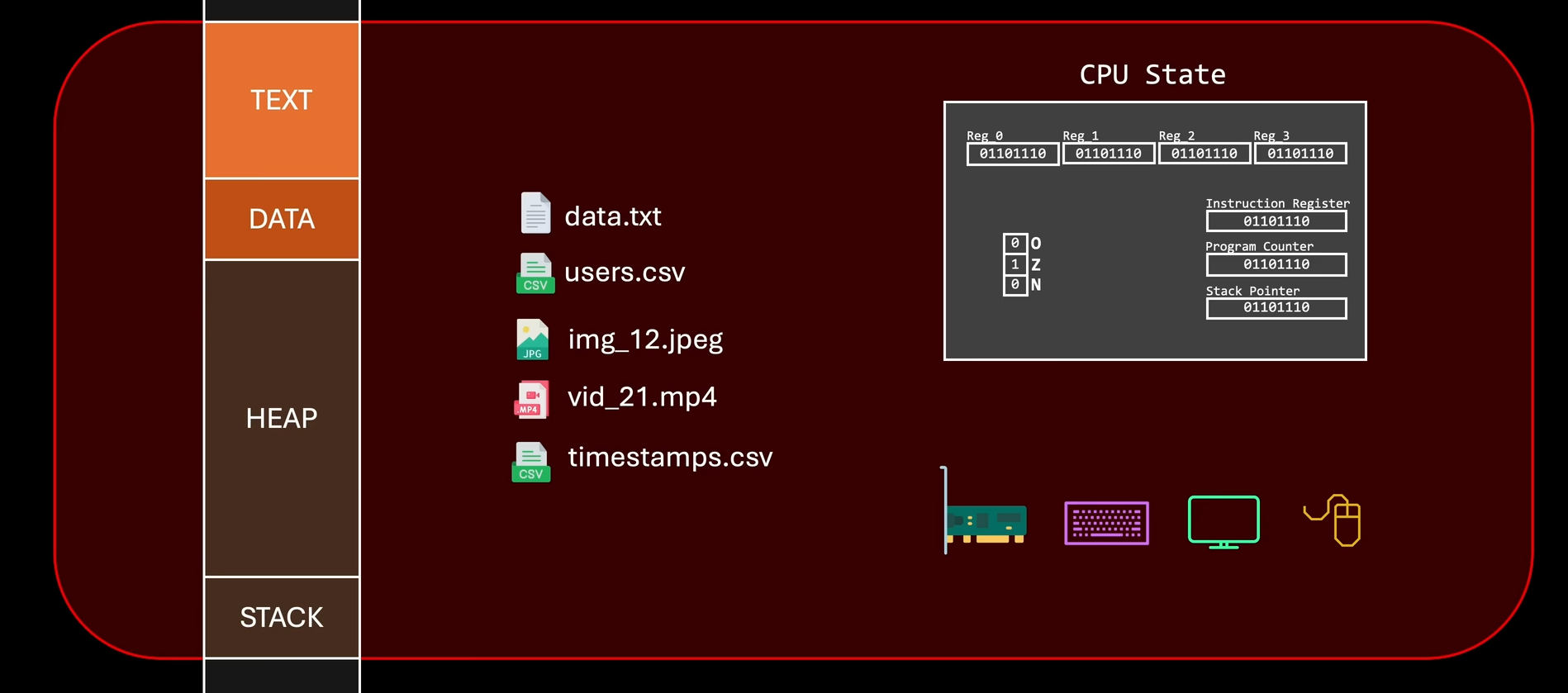
一个进程相当于一个公司,线程就相当于是公司中的员工。公司可以指定员工的状态,它可以是禁止工作,可以开始工作等,但是公司无法决定员工什么时候工作,工作的效果等。在计算机中,什么时候运行哪个线程由CPU和操作系统决定。
2 多线程和多进程的Python实现
2.1 多线程
from threading import Thread
def func():
for i in range(100):
print('msg from func:', i)
if __name__ == '__main__':
t1 = Thread(target=func)
t1.start()
for i in range(100):
print('msg from main', i)
或者采用面向对象的方法:
from threading import Thread
class MyThread(Thread):
def run(self):
for i in range(100):
print('msg from class MyThread', i)
if __name__ == '__main__':
t1 = MyThread()
t1.start()
for i in range(100):
print('msg from main', i)
2.2 多进程
from multiprocessing import Process
def func():
for i in range(100):
print('msg from func:', i)
if __name__ == '__main__':
p = Process(target=func)
p.start()
for i in range(100):
print('msg from main', i)
在windows系统中,上面的程序会首先执行主进程,再执行子进程。要想先执行子进程,需要调用子进程的join()方法。
2.3 传递参数
通过Thread类的内置属性args元组传递参数:
from threading import Thread
def func(name):
for i in range(100):
print(f'msg from func {i}, name is {name}')
if __name__ == '__main__':
t1 = Thread(target=func, args=('debussy',)) # 传递的参数必须是一个元组,所以要加逗号
t1.start()
for i in range(100):
print('msg from main', i)
通过面向对象的方式传递参数:
from threading import Thread
class MyThread(Thread):
def __init__(self, name):
super(MyThread, self).__init__()
self.name = name
def run(self):
for i in range(100):
print(f'msg from class MyThread {i}, name is {self.name}')
if __name__ == '__main__':
t1 = MyThread(name='debussy')
t1.start()
for i in range(100):
print('msg from main', i)
进程传递参数的方式和线程写法相同,将Thread类改成Process类即可。
3 线程池和进程池
在实际应用中,一个新线程或者新进程的开辟是要付出内存占用的代价的,所以我们也一般不会无限制的开辟新线程。通常可以创建一批线程(进程),让这些线程(进程)可以被重复利用。我们可以开辟一个线程池(进程池),用户直接将任务提交给线程池(进程池),而具体的任务调度和重复利用不需要用户关心,由操作系统帮助用户完成。
from concurrent.futures import ThreadPoolExecutor
# from concurrent.futures import ProcessPoolExecutor
def func(name):
for i in range(100):
print(f'msg from {name}, {i}')
if __name__ == '__main__':
with ThreadPoolExecutor(50) as t: # 开辟50个线程的线程池
for i in range(100): # 将100个任务提交给这个线程池
t.submit(func, name=f'任务{i}')
print('done!') # 守护,即线程池中的任务全部执行完毕才会继续执行
4 协程
一般情况下,当程序处于IO操作时,线程都会处于阻塞状态。协程就是当程序阻塞时选择性的切换到其他任务上,从而在单线程的情形下大大提升CPU的利用率。在微观上,CPU在不同的任务之间来回切换,而在宏观上,表现为多个任务在同时执行。
在课程的讲解中,并没有提及时间片流转的概念。这可能就是类似windows,linux的操作系统在实时性上不如RTOS的原因。
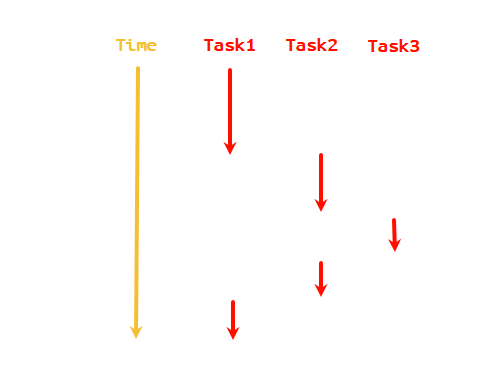
协程是可以暂停运行和恢复运行的函数,在Python中可以由协程函数定义。协程函数是开头为async def的函数。它和普通的函数最大的不同在于当运行它时它不会真的执行里面的代码,而是返回一个协程对象,执行协程对象时才执行里面的代码。
当函数中出现await时,就会暂停运行,让出CPU占用权,当await后的内容完成之后再请求控制权恢复运行。拥有CPU控制权的协程可以运行,没有CPU控制权的协程只能等待。await后的协程会被包装成一个任务,让事件循环调度,但是前提是await后的东西是一个协程。如果await后的内容已经是一个任务了,就不用包装了。等待await后的任务执行完,会返回任务返回的结果(当然,如果任务本身不返回结果,也可以不返回)。

任务是对协程的包装,它不仅包含了协程本身,还记录了协程的状态。这个状态可以是准备执行、正在运行或者已完成等。
事件循环充当了调度器的角色,它在程序中循环往复做三件事:检查协程(拿到CPU控制权后检查当前可以运行的协程),让出控制(将控制权转移给可以执行的协程),等待控制权(等当前协程暂停或者运行完成回收控制权)。
所以,当需要实现协程异步的时候,也只需要完成以下三步:
- 定义协程函数
- 包装协程为任务
- 建立事件循环
第一步和第三步都比较简单,而第二步包装协程为任务有多种方式。
直接将函数包装成任务:
import asyncio
from time import perf_counter
async def fetch_url(url):
print('msg from fetch_url.')
await asyncio.sleep(1)
print('fetch_url is done!')
return 'fetch_url content'
async def read_file(filepath):
print('msg from read_file.')
await asyncio.sleep(2)
print('read_file is done!')
return 'read_file content'
# 如果要在main函数中使用await获取任务的返回值,那么main函数必须是一个async标记的异步函数
async def main():
url = 'https://example.com'
file_path = './example.txt'
# 创建两个任务
task1 = asyncio.create_task(fetch_url(url))
task2 = asyncio.create_task(read_file(file_path))
# 使用await等待任务完成,并获取返回值
fetch_result = await task1
file_result = await task2
print(fetch_result, file_result)
if __name__ == '__main__':
start_time = perf_counter()
asyncio.run(main()) # 开启事件循环
end_time = perf_counter()
print(f'Time taken: {end_time - start_time:.2f} seconds.')
asyncio.gather():接受多个协程,返回一个协程,使用await就可以获得结果的列表,返回的顺序和传入的顺序相同。gather会等待所有的任务完成后才进行后续数据处理。
import asyncio
from time import perf_counter
async def fetch_url(url):
print('msg from fetch_url.')
await asyncio.sleep(1)
print('fetch_url is done!')
return 'fetch_url content'
async def read_file(filepath):
print('msg from read_file.')
await asyncio.sleep(1)
print('read_file is done!')
return 'read_file content'
# 如果要在main函数中使用await获取任务的返回值,那么main函数必须是一个async标记的异步函数
async def main():
url = 'https://example.com'
file_path = './example.txt'
# 使用await获取任务返回的结果列表,返回的顺序和传入的顺序一样
results = await asyncio.gather(fetch_url(url), read_file(file_path))
# 使用await等待任务完成,并获取返回值
print(results)
if __name__ == '__main__':
start_time = perf_counter()
asyncio.run(main()) # 开启事件循环
end_time = perf_counter()
print(f'Time taken: {end_time - start_time:.2f} seconds.')
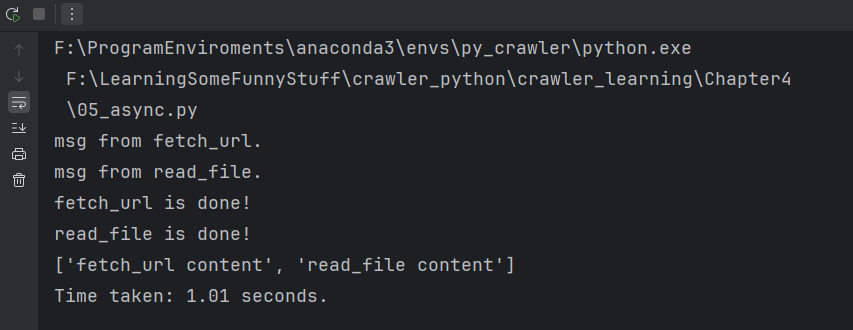
asyncio.as_completed():接受一个包含协程的可迭代对象(列表),返回一个包含结果的迭代器,迭代器会按照协程完成的顺序依次生成结果,如果没有结果就等待。
import asyncio
from time import perf_counter
async def fetch_url(url):
print('msg from fetch_url.')
await asyncio.sleep(2)
print('fetch_url is done!')
return 'fetch_url content'
async def read_file(filepath):
print('msg from read_file.')
await asyncio.sleep(1)
print('read_file is done!')
return 'read_file content'
# 如果要在main函数中使用await获取任务的返回值,那么main函数必须是一个async标记的异步函数
async def main():
url = 'https://example.com'
file_path = './example.txt'
# 获取完成结果的迭代器
results = asyncio.as_completed([fetch_url(url), read_file(file_path)])
# 使用await等待任务完成,并获取返回值
for result in results:
print(await result)
if __name__ == '__main__':
start_time = perf_counter()
asyncio.run(main()) # 开启事件循环
end_time = perf_counter()
print(f'Time taken: {end_time - start_time:.2f} seconds.')
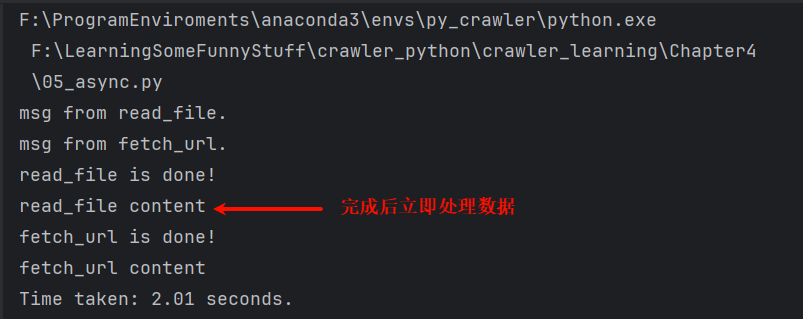
对于爬虫,可以使用下面的程序结构(python=3.12):
import asyncio
from time import perf_counter
async def get_data(url):
print(f'start down load data from {url}. ')
await asyncio.sleep(1)
print('Download finished.')
return f'data from {url}'
async def main():
tasks = []
urls = [
'https://www.baidu.com',
'https://www.bilibili.com',
'https://www.163.com'
]
for url in urls:
t = get_data(url)
tasks.append(t)
results = asyncio.as_completed(tasks)
for result in results:
print(await result) # 任务完成后立即处理数据
if __name__ == '__main__':
start_time = perf_counter()
asyncio.run(main())
end_time = perf_counter()
print(f'Time token {end_time - start_time:.2f} seconds. ')
main函数还可以写成:
async def main():
tasks = []
urls = [
'https://www.baidu.com',
'https://www.bilibili.com',
'https://www.163.com'
]
for url in urls:
t = get_data(url)
tasks.append(t)
await asyncio.gather(*tasks) # *tasks 对序列的解包操作,这个序列可以是元组,也可以是列表
或者:
async def main():
tasks = []
urls = [
'https://www.baidu.com',
'https://www.bilibili.com',
'https://www.163.com'
]
for url in urls:
task = asyncio.create_task(get_data(url)) # get_data(url)返回一个协程对象,使用create_task()函数将其包装成一个task
tasks.append(task)
await asyncio.wait(tasks) # 等待所有的任务完成
5 aiohttp模块(aiofiles)
aiohttp模块需要安装(aiofiles同理):
conda install aiohttp
pip install aiohttp
import asyncio
import os
import aiohttp
async def download_img(url):
img_name = './img/' + url.split('/')[-1]
async with aiohttp.ClientSession() as session: # 异步的 with 前必须加async
async with session.get(url) as resp:
with open(img_name, mode='wb') as f: # 同步的 with 打开文件,不加async
f.write(await resp.content.read())
# 如果要读取文本,使用resp.text()
# 如果要获取json,使用resp.json()
print(f'file {img_name} download done!')
async def main():
urls = [
'https://pic3.zhimg.com/v2-e27b6692c148f856de9ff7da8a23c046_r.jpg',
'https://www.bizhigq.com/pc-img/2023-07/g4460.jpg'
]
tasks = [asyncio.create_task(download_img(url)) for url in urls]
await asyncio.gather(*tasks)
if __name__ == '__main__':
if not os.path.exists('./img'):
os.mkdir('./img')
asyncio.run(main())
实测发现,某些壁纸网站的图片下载之后无法打开,但是直接在bing搜图中搜到的图片可以正常下载。
下面是爬取西游记小说的例程:
import asyncio
import json
from time import perf_counter
import aiofiles
import aiohttp
import requests
import os
async def get_content(title, bid, cid):
data = {
'book_id': bid,
'cid': bid + '|' + cid,
'need_bookinfo': 1
}
data = json.dumps(data)
url = f'https://dushu.baidu.com/api/pc/getChapterContent?data={data}'
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
data = await resp.json() # 用await拿到数据
content = data['data']['novel']['content']
async with aiofiles.open('./novel/' + title + '.txt', mode='w', encoding='utf-8') as f:
await f.write(content)
async def get_catalog(url, bid):
resp = requests.get(url)
dic = resp.json()
tasks = []
for item in dic['data']['novel']['items']:
title = item['title']
cid = item['cid']
tasks.append(asyncio.create_task(get_content(title, bid, cid)))
await asyncio.gather(*tasks)
resp.close()
if __name__ == '__main__':
if not os.path.exists('./novel'):
os.mkdir('./novel')
start_time = perf_counter()
book_id = '4306063500'
catalog_url = 'https://dushu.baidu.com/api/pc/getCatalog?data={%22book_id%22:%22' + book_id + '%22}' # %22 就是字符 "
asyncio.run(get_catalog(catalog_url, book_id))
end_time = perf_counter()
print(f'Done! Time taken {end_time - start_time:.2f} seconds.')
实测下载用时0.7到1.2秒左右。
原创笔记,码字不易,欢迎点赞,收藏~ 如有谬误敬请在评论区不吝告知,感激不尽!博主将持续更新有关嵌入式开发、FPGA方面的学习笔记。